Source code:
Click here for a Demo
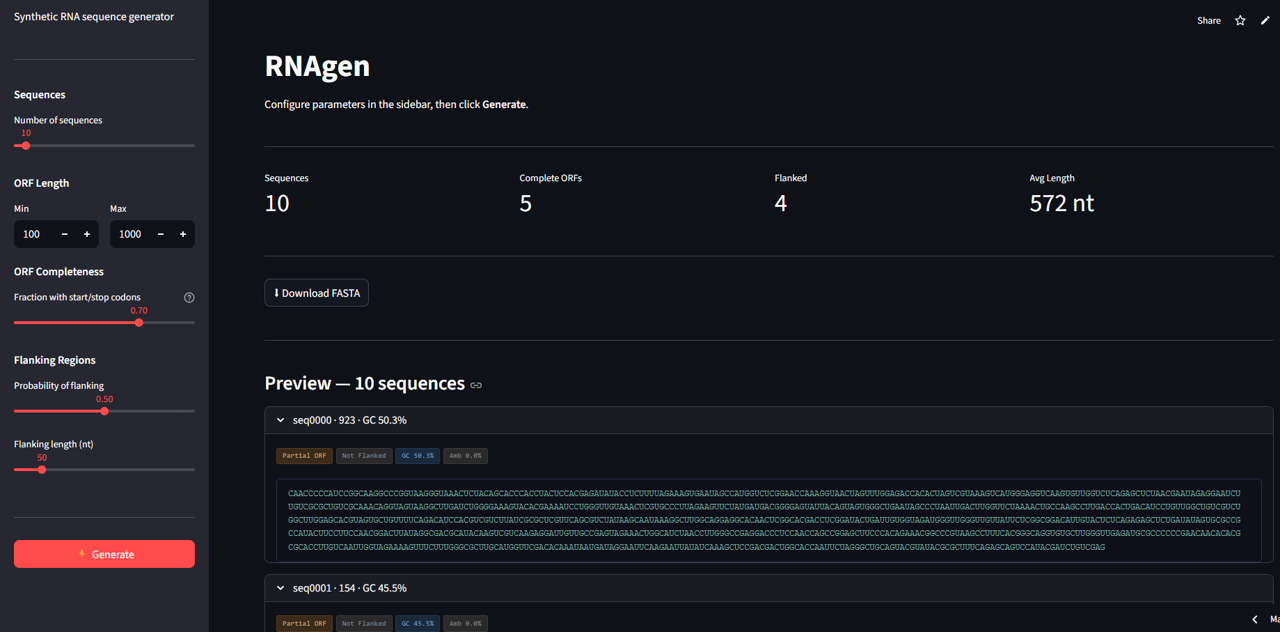
Demo UI built using Streamlit
Background:
Experimental RNA sequencing pipelines and bioinformatics tools require large volumes of test data to validate correctness, benchmark performance, and stress-test edge cases. This data is often unavailable early in development or impractical to source from wet lab experiments.
Synthetic data generation fills this gap by providing reproducible, configurable datasets that can be produced instantly and tailored to the requirements of a given pipeline or experiment.
Description:
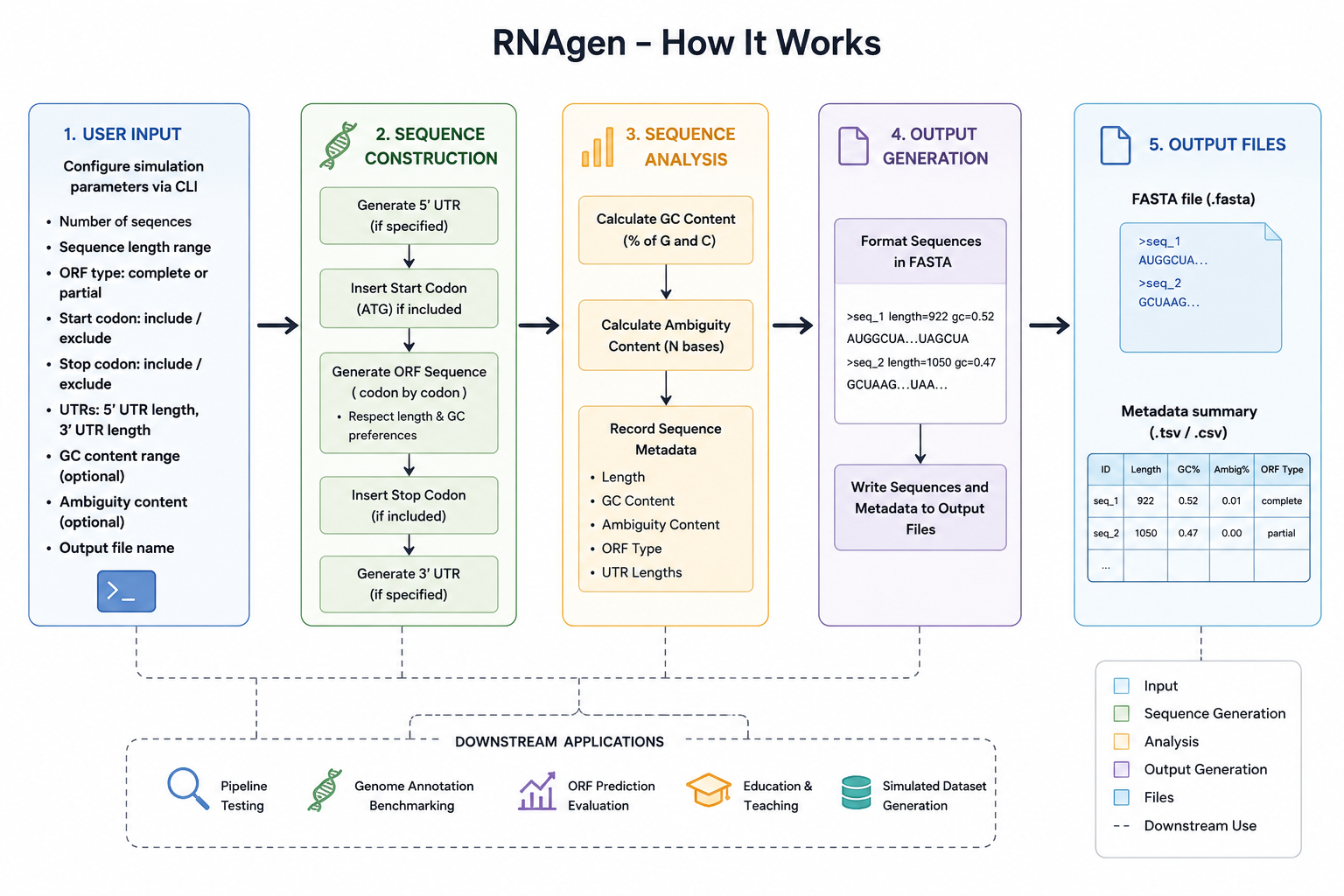
RNAgen generates synthetic RNA sequences with configurable biological properties and outputs them in standard FASTA format:
>seq_001 length=523 gc_content=45.5 ambiguity=0.0 type=complete flanked=yes
ACGUACGUACGUACGUAUGCCCUACGUACGUACGUACGUACGUACGUACGUAA
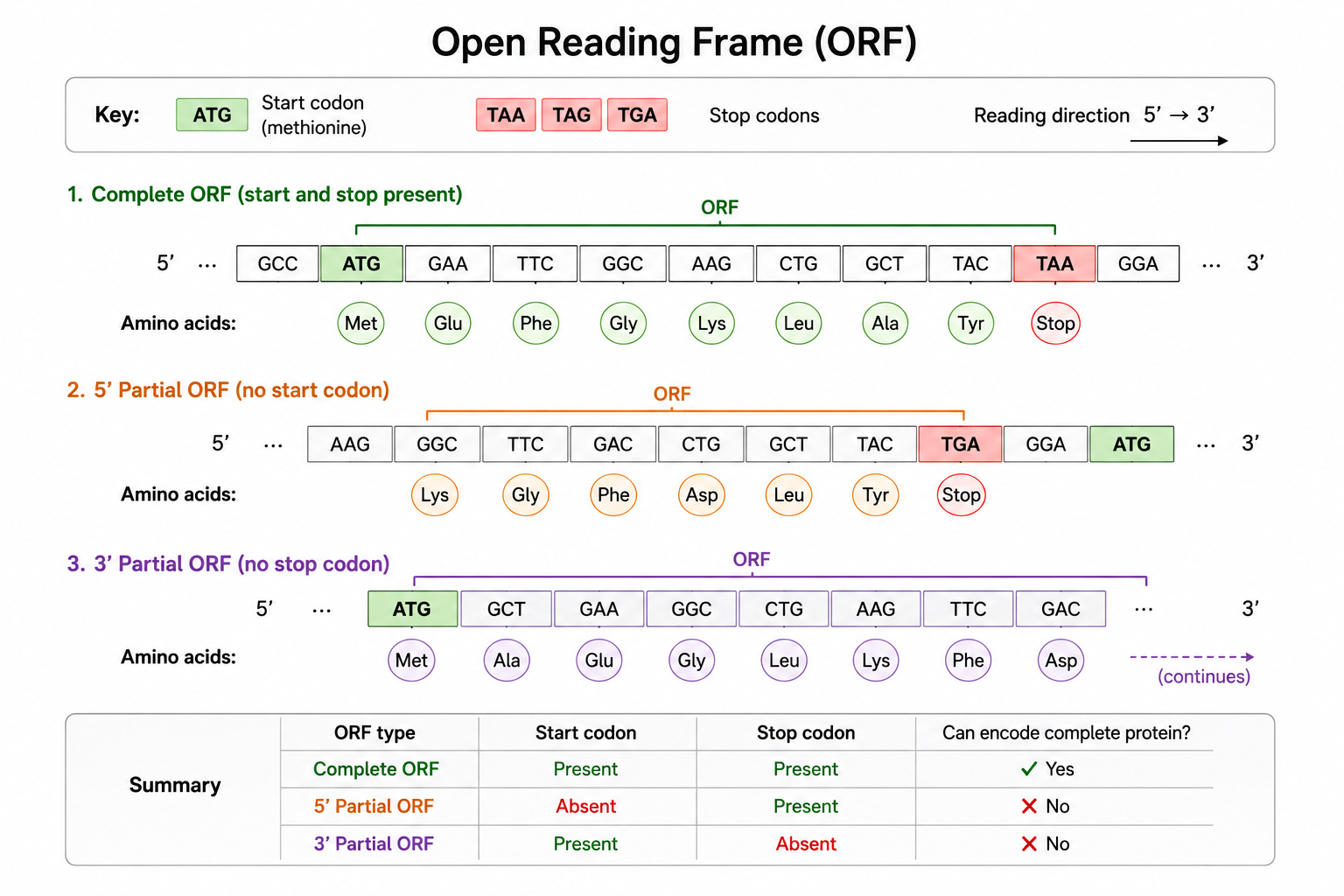
Each sequence is constructed with an open reading frame (ORF) that is either complete (containing an authentic AUG start codon and a UAA, UAG, or UGA stop codon) or partial (simulating incomplete or degraded transcript reads).
Optional flanking regions can be added to either side of the ORF to reflect the untranslated regions present in real transcript architecture. Sequence length, ORF completeness ratio, flanking probability, and flanking length are all user-controlled, allowing targeted simulation of specific biological conditions.
The FASTA output is immediately compatible with downstream tools such as BLAST, RNA-seq aligners, and ORF prediction software.
How It Works:
RNAgen is built around a Simulator class that accepts user-defined parameters and orchestrates sequence generation.
The CLI entry point in main.py handles argument parsing and validation before passing a configuration namespace to the Simulatorclass.
When a run is initiated, the class iterates over the requested number of sequences, randomly determining for each whether it will be a complete or partial ORF based on the configured completeness ratio. Complete ORFs are assembled codon by codon — starting with AUG, filling the body with randomly selected codons, and terminating with a randomly chosen stop codon. Partial ORFs bypass this structure and are generated as raw random nucleotide sequences of the specified length.
Flanking regions are added probabilistically, with independent random sequences appended to the 5′ and 3′ ends of the ORF when the flanking probability threshold is met.
Each generated sequence is paired with a metadata description capturing its length, GC content, ambiguity content, ORF type, and flanking status, all computed via utility functions in the sequence_lib.py module. The full set of results is stored as a list of tuples containing the sequence ID, description, and sequence string. Once generation is complete, results are written to disk in FASTA format.